SQL Server’da Index Kavramı ve Performansa Etkisi
Indexler veriye daha hızlı ve daha az okuma yaparak ulaşmamızı sağlar.
Somut bir örnek olması açısından, bir kitabın içindekiler bölümü olmasa kitabın içinde aradığınız konuyu nasıl bulacağınızı düşünün. Bütün kitabı baştan sona okumanız gerekirdi. Index olmayan bir tabloda bir select ifadesinin aradığı kaydı bulması için bu şekilde tüm tabloyu okuması gerekir. Bu işleme table scan denir. Özellikle performans iyileştirmesi yaparken sorgunun execution plan’ına baktığımızdan görmek istemeyeceğimiz bir durumdur. Execution Plan hakkında daha detaylı bilgi almak için sitemizin arama kısmına Execution Plan yazmalısınız.
Peki kitabın içinde içindekiler bölümünün olduğunu düşünün. Bu bölüme bakarak istedeğiniz konunun hangi sayfada olduğunu daha az okuyarak ve daha hızlı bir şekilde bulabilirsiniz. İşte index olan bir tabloda da bu şekilde aradığımız veriyi kolayca bulabiliriz.
Indexler B-tree yapısında çalışırlar. Peki nedir bu B-tree yapısı?
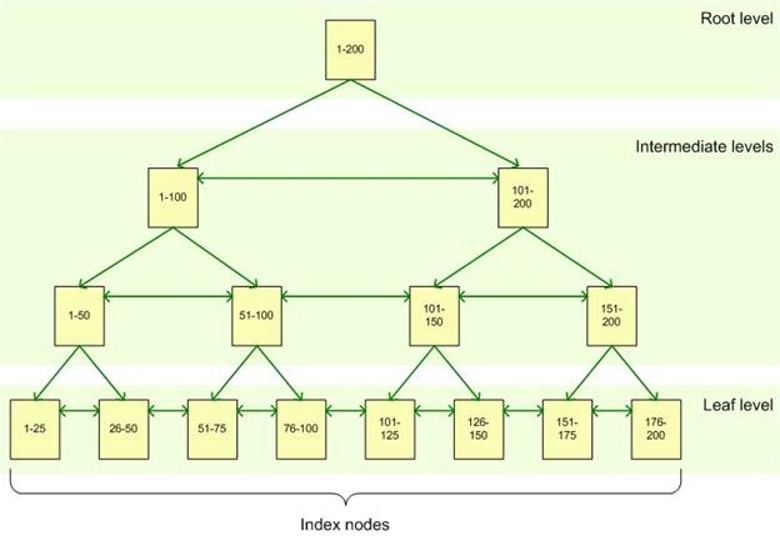
B tree yapısı 3 leveldan oluşur. Aşağıdaki resimde detayını görebilirsiniz. Aşağıdaki resimi bir örnekle daha detaylı inceleyelim. Tablomuzdaki bir kolonumuzda 1’den 200’e kadar değerler olsun. Bu kolon’a index koyalım.
Root Level: B tree ağaç yapısındaki en üst page’dir. Index üzerinde arama yapıldığında arama buradan başlar ve ağacın alt tarafına doğru ihtiyacı olan veriyi bulmak için arama işlemi devam eder. Resimde gördüğünüz gibi Root Level Page’de bu index’te 1’den 200’e kadar değerler bulunuyor. Aradığımız veriyi bulmak için hangi intermediate level’e gitmemiz gerektiğinide görebilirsiniz.
Intermediate Levels: Root Level Page’den sonra intermediate level page’ler gelir. Index’in büyüklüğüne göre bir ya da birden fazla intermediate level vardır. Aşağıdaki resimde gördüğünüz örnekte 2 tane intermediate level var. Örneğin değeri 123 olan kaydı aradığımızı düşünelim. Önce root level’e geliyoruz. Ardından 101-200 arasındaki değerleri işaret eden intermediate level’deki page’e gidiyoruz. Ardından bu page’de bizi hemen altındaki 101-150 arasındaki değerleri işaret eden diğer intermediate level page’ e yönlendiriyor.
Leaf Level: Leaf Level B tree yapısının son kısmıdır. Örneğimize devam edersek, arama işlemi 101-150 arasındaki kayıtları işaret eden intermediate level page’e geldiğinde bu intermediate level’den 101-125 arasındaki leaf level page’e yönlenecektir. Index’in tipine göre(Clustered ya da Non Clustered) verinin kendisi ya da verinin yerini işaret eden pointer’ın olduğu level’dir. Clustered ve Non Clustered Index arasındaki farkları detaylı olarak incelemek için “Clustered Index ve Non Clustered Index Farkları” isimli makalemi okumanızı öneririm.

Index’leri oluştururken dikkatli olmalıyız. Veritabanıdaki transaction yoğunluğu ve veritabanının kullanım amacına göre index oluşturup oluşturmayacağımıza karar vermeliyiz. Örneğin tabloda çok yoğun update ya da insert ya da delete işlemleri oluyorsa bu tabloya index koyarken biraz düşünmeliyiz. Çünkü yapılan her update ya da insert ya da delete işlemi index’e de uygulanacaktır. Dolayısıyla index koyarsak update,insert ve delete işlemleri yavaşlayacaktır. Uygulamacıyı bu konuda uyarmalıyız. Buna rağmen sisteme çok fazla yükü olan bir sorgu varsa ve koyacağımız bir index bu select’i ciddi anlamda hızlandıracaksa koymayı tercih edebiliriz.
Update,insert,delete yükü çok olmayan, daha çok select ile arama yapılan bir tablo ise ihtiyacımız olan index’leri koymak select performansını arttıracağı için index koyabiliriz.
Index koyarken birden fazla kolonu bir araya getirerek index koyabilirsiniz. Bu tip indexlere composite index denir. Örneğin select a from table1 where b=3 and c=4 isimli bir sorgunuz var. Index’i hem b hem de c kolonunu içerecek şekilde koyabilirsiniz. Birden fazla kolonu koyabilirsiniz ama index’in boyutu 900 byte’ı geçmemelidir. Oluşturmak istediğiniz index’in boyutu 900 byte’tan fazlaysa aşağıdaki gibi bir uyarı alırsınız. SQL Server 2016’da bu sınır 1700 byte oldu.
Warning! The maximum key length is 900 bytes. The index ‘a’ has maximum length of 3402 bytes. For some combination of large values, the insert/update operation will fail.
Boyutu 900 byte’tan büyük bir index’e insert yapmak istediğinizde de aşağıdaki gibi bir hata alabilirsiniz.
Msg 1946, Level 16, State 3, Line 11
Operation failed. The index entry of length 3402 bytes for the index ‘a’ exceeds the maximum length of 900 bytes.
900 byte aslında çok büyük bir rakam. Ben index koyarken önce tablodaki kolon sayısına bakıyorum. Örneğin tablo 20 kolon olsun. 3 kolon’u ve 2 tane de included kolonu olan bir index koymam gereksin. Eğer bu index uygulamanın performansını çok arttıracaksa koymayı düşünürüm. Ama hiçbir zaman 20 kolonlu bir tabloda 3 ya da 4 kolondan fazla index oluşturmam. Çünkü olay tabloyu ayrıca birde index’te oluşturmaya doğru gider.
Index’te included kolon nedir?
Clustered index olan bir tabloda A kolonuna non clustered index koyduğumuzu farzedelim. Sorgu da “select B from table1 where A=3” olsun. Sorgu A kolonundaki index’e giderek aramasını yapacak ve leaf level’ine geldiğinde clustered index key’i bulacak. Daha sonra bu clustered index key bilgisi ile clustered index’e giderek ihtiyacı olan veriyi bulacak. Bu işleme key lookup deniyor. Key lookup yapmadan yani clustered index’e gitmeden sadece index’i kullanarak ihtiyacını sağlamak için A kolonuna koyduğumuz index’e included alan olarak B kolonunu koyarsak sorgu sadece index üzerinde ihtiyacı olan veriyi bulabilecek. Bu tip nonclustered indexlere de Covering Index denir.
Makalemin başında anlattığım gibi Index’ler diste tablolardan ayrı olarak tutulurlar ve tabloda yapılan insert,update ve delete işlemleri index’lere uygulanır. Bu yüzden index’ler fragmante olurlar.
Peki index fragmentation nasıl oluşur?
İndex’imizi oluşturduk. Ve bir süre boyunca tabloda sürekli update, delete ve insert işlemlerini gerçekleştirdik. Delete ettiğimizi düşünelim. Index’in bir page’inden biraz veri silmiş olduk. Sonra başka bir kayıt insert etmek istedik. Ve bu kayıt sildiğimiz page’de yeterli yer olmadığı için sql server gitti bu kaydı yeni bir boş page’e yazdı. Bu şekilde index’ler zamanla diskte dağınık halde tutulmaya başlar ve fragmentation arttıkça index’in performansı azalır. Yoğun update ve delete içeren tablolar da index’lerin çabuk fragmante olmalarını engellemek için index’e fill factor koyabilirsiniz.
Peki Fill factor nedir?
Index’lerini create ya da rebuild ederken fill factor parametresini belirtebilirsiniz. Örneğin fill factor’ü %90 olarak set ederseniz Leaf Level page’lerin %90’unu doldurur ve %10’unu boş bırakır. Bu şekilde leaf level page’e kayıt eklemek istediğinde yeteli boş alanı bulur ve index’in diskte dağılması problemini geciktirmiş olur. Fill Factor ‘u index’inizin fragmante olma hızına göre set edebilirsiniz. Ama unutmayın index’inizdeki leaf level page’lerin sonuna boş alan ekleyeceği için boyutunu arttıracaktır.
Fill factor ile Leaf Level page’lerin sonuna boşluk eklediğimizi söyledik. Index’i create ya da rebuild ederken fill factor belirlemişsek birde pad_index=on seçeneğini kullanabiliriz. Pad_index’i aktif edersek fill factor ile leaf level page’lerin sonuna konan oran kadar boşluk intermediate level page’lere de konulur. Ama performans anlamında çok bir önem arz ettiğini söyleyemem. Ben genel olarak Fill Factor’ü %90 olarak set ediyorum. Hatta bunu server seviyesinde konfigure ediyorum. “sp_configure(SQL Server’da Server Seviyesinde Konfigurasyonlar)” isimli makalemi okumak isteyebilirsiniz. Pad_Index’i off olarak bırakıyorum. Tabi bazı durumlarda bazı indexler için özel olarak fill factor’u %80 hatta %70’lere çekebilirsiniz. Bu tamamen index’inizin ne sıklıkla fragmante olduğu ile ilgili.
Indexlerinizin sık bir şekilde fragmante olması sorununu geciktirmek için fill factor seçeneği bizim için güzel bir özellik. Fakat eninde sonuna indexler fragmante olur. Bu yüzden düzenli olarak indexleri rebuild ya da reorganize edecek bir job oluşturmalısınız.
OLA HALLENGREN sql server bakım işlemleri için çok güzel script’ler hazırlamış. Ben bu script’leri kullanıyorum size de kullanmanızı tavsiye ederim. “SQL Server Maintenance/Bakım İşlemleri(OLA HALLENGREN)” isimli makalemde OLA HALLENGREN’in job’ını nasıl konfigure edeceğimizi anlattım.
Index’lerle ilgili daha detaylı bilgi için aşağıdaki makalere göz atmak isteyebilirsiniz.
“Index Oluştururken Sorgudaki Order By Yönüne Bakmak(ASC,DESC)“,
“Index Oluşturuken GROUP BY İfadesindeki Kolona Dikkat Etmek“,
“Index Oluştururken JOIN Yapılan Kolonlara Dikkat Etmek“,
“Kullanılmayan Index’leri Tespit Etmek“,
“Eksik Index’leri Tespit Etmek“,
“SQL Server’da Tablo ve Index Büyüklükleri“,
“Indexed View Nedir Ve Nasıl Oluşturulur“,
“ColumnStore Index Nedir ve Nasıl Kullanılır?“,
“Extended Events Kullanarak Online Index Rebuild İşlemlerinin Yüzde Kaçta Olduğunu Görmek“
![]()