Isolation Levels 3
Bu makalede RCSI ve Snapshot Isolation farklarını ve bu Isolation Level’leri kullandığımız’da oluşabilecek tutarsızlıkları inceleyeceğiz.
İki Isolation Level’da da;Tempdb’de yeterince yer olmazsa, update’ler fail olmaz fakat versiyonlamada yapamaz. Bu yüzden selectler fail olabilir.
Snapshot Isolation Level’ında update’ler conflict olabilir. RCSI’da bu gerçekleşmez.
RCSI, Snapshot Isolation Level’a göre, tempdb’de daha az yer tüketir.
RCSI Distrubuted Transaction ile çalışabilirken Snapshot çalışamaz.
RCSI tempdb,msdb ya da master veritabanlarında enable edilemez.
SNAPSHOT Isolation Level’da global temp tablo oluştururken tempdb’de SNAPSHOT’a izin verilmelidir.
SNAPSHOT Isolation Level’da, DDL Statement ile herhangi bir obje modifiye edildiği anda, başka bir transaction aynı nesneye erişirse DDL Statement’ı fail olacaktır. Aşağıdaki örnekte görebilirsiniz.
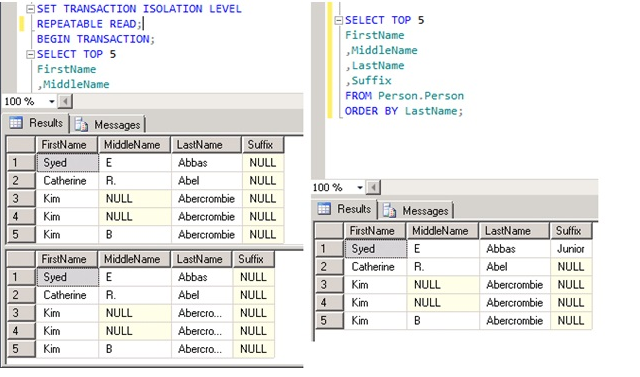
İlk session’da aşağıdaki scripti çalıştıralım.
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
BEGIN TRANSACTION
ALTER INDEX AK_Employee_LoginID
ON HumanResources.Employee REBUILD;
GO
WAITFOR DELAY '00:00:10.000';
COMMIT TRANSACTION
İkinci sessionda’da da aşağıdaki scripti çalıştıralım.
SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION SELECT TOP 1000 [BusinessEntityID] FROM [AdventureWorks2012].[HumanResources].[Employee] where LoginID='adventure-works\rob0' COMMIT TRANSACTION
İlk session aşağıdaki hata ile sonuçlanacaktır.
Transaction failed because this DDL statement is not allowed inside a snapshot isolation transaction. Since metadata is not versioned, a metadata change can lead to inconsistency if mixed within snapshot isolation.
Msg 3902, Level 16, State 1, Line 2
The COMMIT TRANSACTION request has no corresponding BEGIN TRANSACTION.
Aşağıda hangi DDL işlemlerinin kısıtlandığını görebilirsiniz.
- CREATE INDEX
- CREATE XML INDEX
- ALTER INDEX
- ALTER TABLE
- DBCC DBREINDEX
- ALTER PARTITION FUNCTION
- ALTER PARTITION SCHEME
- DROP INDEX
- Common language runtime (CLR) DDL
RCSI’da ise böyle bir kısıtlama yok.
RCSI ya da SNAPSHOT kullanırken tempdb’de yeterince yer olması gerektiğini daha önce söylemiştik. tempdb’de versiyonlama yapabilmek için hangi veritabanı ne kadar yer kullanıyor aşağıdaki şekilde görebilirsiniz.
select DB_NAME(database_id) AS DBName,SUM(aggregated_record_length_in_bytes)/1024 [SpaceUsed_KB] from sys.dm_tran_top_version_generators GROUP by database_id ORDER by SpaceUsed_KB DESC
SNAPSHOT’ı ve RCSI’ı kullanırken veride tutarsızlığa neden olabilecek birkaç örneği inceleyelim. Örneklerimizi READ COMMITTED, RCSI ve SNAPSHOT üzerinde tekrarladığımızda farklılıklarını göreceğiz.
1) İlk iki örneğimizde kullanmak için herhangi bir veritabanı üzerinde aşağıdaki scripti çalıştıralım.
create table marbles (id int primary key, color char(5)) insert marbles values(1, 'Siyah') insert marbles values(2, 'Beyaz')
İlk olarak READ COMMITTED üzerinde deneyelim. Yeni bir session açıp aşağıdaki sorguyu çalıştıralım. Transaction’ı başlatıp update’i gerçekleştirdik fakat henüz commit etmedik.
begin tran update marbles set color = 'Beyaz' where color = 'Siyah
ikinci sessionda aşağıdaki sorguyu çalıştıralım. Sorguyu çalıştırdığımızda, ilk sorgu commit olmadığı için beklediğini göreceğiz.
begin tran update marbles set color = 'Siyah' where color = 'Beyaz' commit tran
Daha sonra tekrar ilk session’a geri dönelim ve aşağıdaki gibi commit edelim.
commit tran
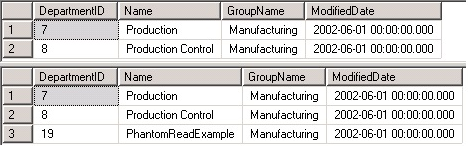
Commit işleminden sonra tablomuza select çektiğimizde sonuç iki Siyah olarak dönecektir. Ve yukarıdaki gibi ilk session’ı commit ettiğimizde ikinci session’da ki bekleme sona erecektir. İlk sorguda rengi siyah olanları beyaza çevirmek istedik, fakat henüz commit etmedik. İkinci sorguda rengi beyaz olanları siyaha çevirmeye çalıştık. Fakat ilk sorgu commit olmadığı için beklemek zorunda kaldık. İlk sorgu tamamlandığında tablomuzdaki iki kayıtta beyaz haline geldi ve ikinci session beyaz olarak bu iki kaydı gördü ve ikisinide siyaha çevirdi.
Örneğimizi RCSI üzerinde tekrarladığımızda da aynı sonuçları alacağız. RCSI pessimistic write yaptığı için ikinci session READ COMMITTED örneğine olduğu gibi bekleyecek.
SNAPSHOT üzerinde örneğimizi tekrarlayıp ne olacağını görelim. Veritabanı bazında SNAPSHOT’a izin verelim. Ve ilk sessionda aşağıdaki scripti çalıştıralım.
set transaction isolation level snapshot begin tran update marbles set color = 'Beyaz' where color = 'Siyah'
ikinci sessionda ise aşağıdaki scripti çalıştıralım.
set transaction isolation level snapshot begin tran update marbles set color = 'Siyah' where color = 'Beyaz' commit tran
Diğer iki Isolation Level’dan farklı olarak, Snapshot Isolation Level optimistic write yaptığı için ikinci session burada beklemeyecektir. Ve sonuçta 1 rows affected şeklinde dönecektir. Tekrar birinci session’a dönüp commit yaptığımızda verinin son halini Beyaz Siyah olarak görürüz. Snapshot’ta farklı kayıtların update edilmesine izin verildi fakat yukarıdaki gibi bir senaryoda uygulama snapshot davranış şekli göz önüne alınarak yazılmadıysa sıkıntılara neden olabilir. Bu senaryoyu uygulamalarınıza göre düşündüğünüzde optimistic write’ın bazı sakıncaları olduğunu görebilirsiniz.
Yalnız bu senaryoyu aynı kaydın update edilmesi ile karıştırmamak gerekir.Eğer yukarıdaki örneği aynı kaydı update edecek şekilde dönüştürürseniz ikinci session’ın beklediğini ve birinci session commit edildiğinde ikinci session’ın update conflict yaşadığını göreceksiniz.
2) İkinci örneğimizde aynı tabloyu kullanarak RCSI ile alakalı bir sıkıntıya değineceğiz.
Öncelikle örneğimizi READ COMMITTED üzerinde gerçekleştirelim. Aşağıdaki sorguyu ilk session’da çalıştıralım.
DECLARE @id INT; BEGIN TRAN SELECT @id = MIN(id) FROM dbo.marbles WHERE color = 'Siyah'; UPDATE dbo.marbles SET color = 'Beyaz' WHERE id = @id;
Yukarıdaki sorgu ile rengi siyah olanlardan id’si en küçük olan’ın id değerini lokal @id değişkenimize atıyoruz ve daha sonra id’si @id değişkenimizle aynı olan kayıtları Beyaz’a çeviriyoruz. Aslında yaptığımız işlem Siyah olanları beyaza çevirmek. Fakat bu işlemi direk update ile yapmıyoruz. Öncelikle select ile çekip lokal değişkenimize atıyoruz. İlk session’ı commit etmeden ikinci session’da aşağıdaki sorguyu çalıştırıyoruz.
DECLARE @id INT; BEGIN TRAN SELECT @id = MIN(id) FROM dbo.marbles WHERE color = 'Siyah'; UPDATE dbo.marbles SET color = 'Sarı' WHERE id = @id; COMMIT TRAN GO
İkinci sorguda da rengi siyah olanlardan id’si en küçük olan’ın id değerini lokal @id değişkenimize atıyoruz ve daha sonra id’si lokal @id değişkenimize eşit olan satırın rengini Sarı olarak update ediyoruz.Fakat sorgunun beklediğini göreceğiz. Tekrar ilk session’a geçip commit işlemini gerçekleştirdiğimizde ikinci session 0 rows affected şeklinde sonuç döndürecek. Verinin son haline baktığımızda Beyaz Beyaz olarak göreceğiz. İkinci session ilk session bitene kadar update edilmiş ama commit edilmemiş veriyi okuyamadı. İlk session commit edildiğinde, ikinci session commit edilmiş veriyi okuyabildi fakat rengi siyah olan bir satır bulamadığı için herhangi bir update gerçekleştirememiş oldu.
Aynı örneği RCSI kullanarak gerçekleştirdiğimizde ikinci session’ın yine ilk session’ın commit edilmesini beklediğini görüyoruz. Fakat READ COMMITTED’tan farklı olarak, RCSI’da yapılan select, commit edilmemiş verinin en son commit edilmiş haline tempdb üzerinden ulaşabildiği için, ikinci session’da ki ilk select okuma yaparak rengi siyah olanlardan id’si en küçük olan’ın id değerini lokal @id değişkenine aktarabildi. Fakat update beklemeye devam etti. İlk session’ı commit ettiğimizde ise ikinci session tamamlandı ve 1 rows affected değerini döndürdü. İlk session Siyah’ı beyaza döndürmüş olsa bile ikinci session id değerini elinde bulundurduğu için update’i id üzerinden gerçekleştirdi. Verinin son haline baktığımızda ise Sarı Beyaz olarak göreceğiz.
Aynı örneği SNAPSHOT kullanarak gerçekleştirdiğimizde ikinci session ilk session’ı yine bekleyecek ve ilk session commit edildiğinde ikinci session update conflict hatasını verecek. Sonuç olarak verinin son hali Beyaz Beyaz olacaktır.
3) Son olarak RCSI veSNAPSHOT Isolation Level’larında oluşabilecek farklı bir soruna değinen bir örnekle makalemi noktalayacağım.
Örneğimizi yine öncelikle READ COMMITTED üzerinde gerçekleştireceğiz. Aşağıdaki sorguyu herhangi bir veritabanında çalıştıralım.
CREATE TABLE Tickets(TicketId INT NOT NULL, AssignedTo INT NOT NULL, Priority VARCHAR(10), CONSTRAINT PK_Tickets PRIMARY KEY(TicketId), ) GO INSERT INTO Tickets(TicketId, AssignedTo, Priority) VALUES(1, 1, 'High') INSERT INTO Tickets(TicketId, AssignedTo, Priority) VALUES(2, 8, 'High') INSERT INTO Tickets(TicketId, AssignedTo, Priority) VALUES(3, 10, 'High') go
Yeni bir query sayfası açıp aşağıdaki scripti çalıştıralım. Bu sorguda, Ticket tablosunda AssignedTo değeri 6 olan ve Priority değeri High olan bir satır yoksa TicketId’si 1 olan satırın AssignedTo değerini 6 olarak set ediyoruz.
BEGIN TRANSACTION UPDATE Tickets SET AssignedTo = 6 WHERE TicketId = 1 AND NOT EXISTS(SELECT 1 FROM Tickets WHERE AssignedTo = 6 AND Priority='High')
Commit işlemini yapmadan ikinci session’a geçip aşağıdaki scripti çalıştıralım. Bu sorguda da ilk koşulumuz yine Ticket tablosunda AssignedTo değeri 6 olan ve Priority değeri High olan bir satır olmaması. Bu şartlar sağlanıyorsa bu sefer TicketId 2 olan satırın AssignedTo değerini 6 olarak set ediyoruz.
UPDATE Tickets SET AssignedTo = 6 WHERE TicketId = 2 AND NOT EXISTS(SELECT 1 FROM Tickets WHERE AssignedTo = 6 AND Priority='High')
İkinci session’ımızda yukarıdaki sorguyu çalıştırdığımızda beklediğini göreceğiz. İlk session’a geri dönüp commit işlemini gerçekleştirdiğimizde ikinci session’da ki bekleme bitecektir ve 0 rows affected olarak değer dönecektir. Çünkü ilk sorgu tamamlandığında ikinci sorguda Ticket tablosunda AssignedTo değeri 6 olan ve Priority değeri High olan bir satır olmaması şartı sağlanamadı. Artık TicketId’si 1 olan satırın AssignedTo değeri 6 olarak gözüküyor.
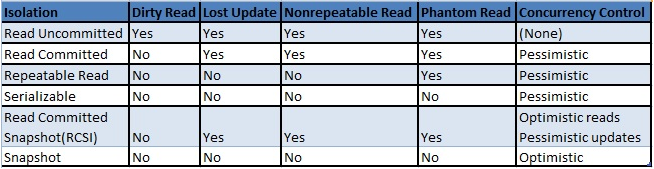
Aynı örneği RCSI ya da SNAPSHOT kullanarak gerçekleştirdiğimizde, ilk session commit olmadan ikinci session’ın çalıştığı anda sonuçlanacağını ve 1 rows affected şeklinde sonuç döndüreceğini göreceğiz. READ COMMITTED’da select commit olmamış veriyi okuyamadığı için, ikinci session’da ki,Ticket tablosunda AssignedTo değeri 6 olan ve Priority değeri High olan bir satır olmaması şartını oluşturan select okuma işlemini gerçekleştiremedi fakat RCSI’da ya da SNAPSHOT’ta bu select en son commit edilmiş halini okuyabildiği için select işlemi gerçekleşti ve bunun sonrasında update yapabildi. İlk session’a dönüp commit işlemini gerçekleştirdiğimizde onunda tamamlandığını ve tablomuzda artık AssignedTo değeri 6 olan ve Prioritry değeri High olan iki tane kayıt olduğunu görebiliriz. Yukarıdaki örnekte aslında tablomuzda AssignedTo değeri 6 olan ve Priority değeri High olan tek bir satır bulunabilmesini amaçladığımız halde, RCSI ya da SNAPSHOT ile bu koşulları sağlayan iki kaydın oluşmasına sebep olduk. Tabiki sorguda yapılacak değişikliklerle RCSI ya da SNAPSHOT kullanarak aynı işlemleri yapabilmek mümkün. Fakat burada göstermek istediğim şey; RCSI ya da SNAPSHOT kullanırsak, uygulamamızda tutarsız veri olabilir. Bunun için uygulamacıları bu konularda uyarmalı ve geçişe karar verildiyse gerekli değişiklikleri yapmasını sağlamalıyız. Aşağıda Hangi Isolation Level’da hangi concurrency sorunlarının meydana gelebileceğini ve isolation Level’ların concurrency kontrol yaklaşımlarını tablo halinde görebilirsiniz.