SQL Server’da her page’in ilk 96 byte’lık bölümü page header olarak adlandırılır. Bu makalemizde page header içinde tutulan verileri detaylı olarak göreceğiz. Yapacağımız örnekleri birebir uygulamak için AdventureWorks2014 veritabanını sisteminize restore edebilirsiniz.
Page Header’ı incelemek için DBCC Page komutunu çalıştırıyorum. DBCC Page ile ilgili detaylı bilgiyi “SQL Server Page Yapısı ve DBCC Page” isimli makaleden okuyabilirsiniz.
DBCC Traceon(3604)
DBCC PAGE('AdventureWorks2014',1,1248,2)
Bu sorgunun sonucunda Page içindeki bilgiler hexadecimal olarak görüntülenecektir. İlk 96 byte’lık yani 192 hexadecimal karakterlik alan Page Header kısmıdır.
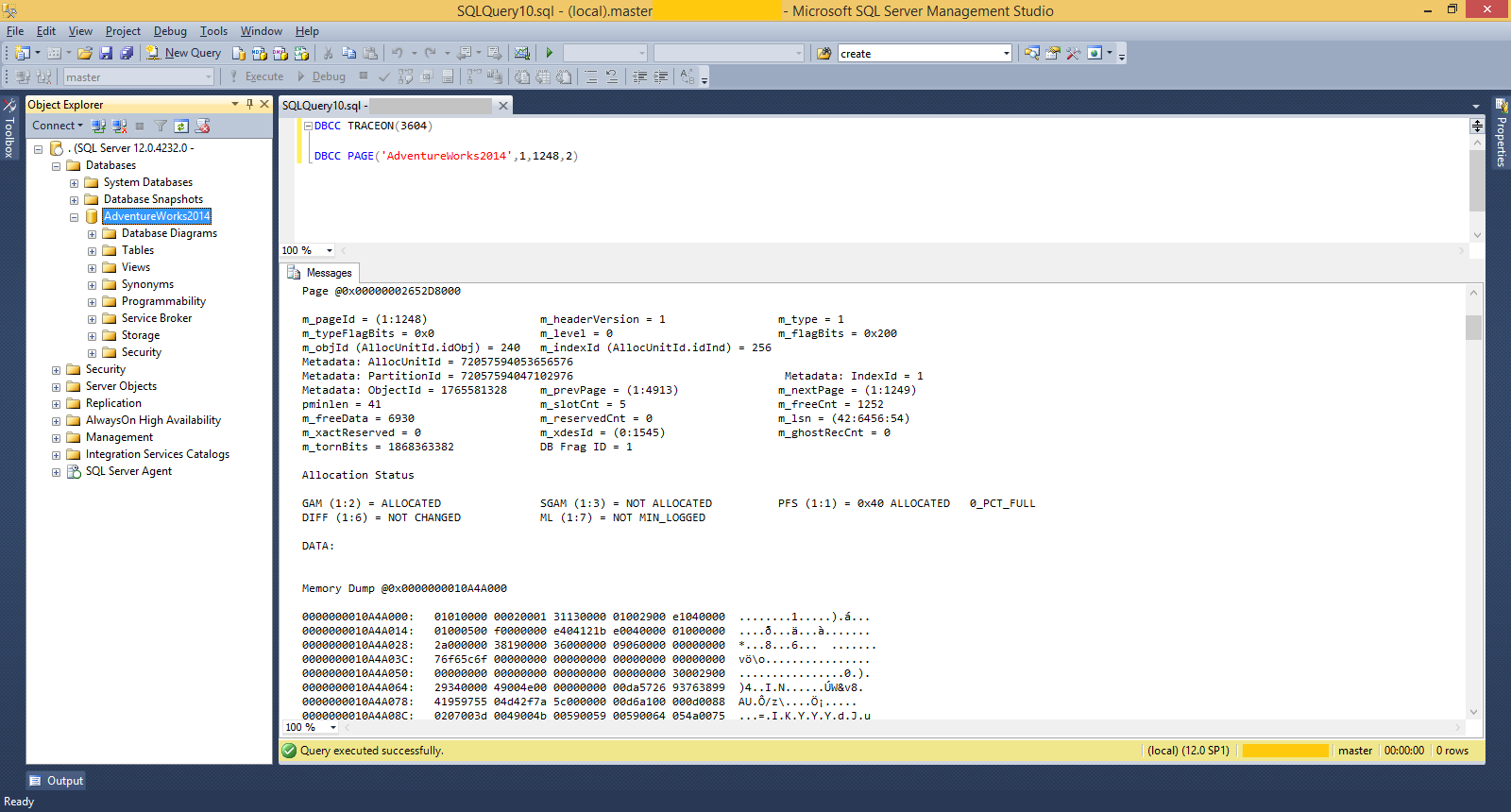
Page Header’da bulunan bilgiler ve Page Header içerisindeki konumları şöyledir. Konumlara bakarken hexadecimal bilgileri 2’li gruplar halinde incelememiz gerekir.(2 hexadecimal 1 byte değerindedir) Bazı bilgiler 1 byte’dan büyük değerler almkatadır. Bu bilgilere ait 2’li hexadecimal grupları sağdan sola doğru okumamız gerekecektir. Üstteki resimde de görüldüğü üzere DBCC Page komutuyla gelen hexadecimal değerler 4’er byte olarak gruplandırılmış. Programlama mantığı gereği ilk veri 0. byte olarak adlandırılsa da, bu makalede 1-4. byte 5-8. byte olarak gruplandırarak anlatacağım.
1.Byte: m_headerVersion =1 (Hexadecimal=01) Page Header Versiyon Bilgisini verir. SQL Server 2000’den bir önceki versiyon olan 7.0’dan itibaren bu değer hep 1 olarak gelmektedir.
2.Byte: m_type =1 (Hexadecimal=01) Page tipini belirtir. Data Page için 1, Index Page için 2, IAM Page için 10 gibi farklı değerlere sahiptir.
3.Byte: m_typeFlagBits=0x0 (Hexadecimal=00) PFS page’ler dışında bu bilgi 0 olarak gelmektedir. Ancak eski versiyonlarda data ve index page’ler için 4 değerini almaktadır.
4.Byte: m_level=0 (Hexadecimal=00) Data Page için 0, Intermediate ve Root Level Page’ler için kaçıncı seviyede olduklarını belirten değeri almaktadır.
5-6. Byte: m_flagbits=0x200 (Hexadecimal=00 02) Bu bilgi 2 byte’lık veriye sahip olduğu için okuma işlemini sağdan sola doğru 02 00 olarak yapmamız gerekecektir. m_flagbits, o page’deki flag’lerin bilgisini verir. Mesela 0x200 ifadesi Checksum kullanıldığını, 0x100 ifadesi ise Torn Page Detection kullanıldığını belirtir.
7-8. Byte: m_indexID= 256 (Hexadecimal=00 01) 256 sayısının hexadecimal karşılığı 01 00’dır m_indexID, ilgili indexin gerçek değerini vermeyebilir. (Mesela bu örnekte Clustered Index olmasına rağmen 256 değerini almış) m_IndexID Allocation Unit ID ‘ye göre Page Header üzerinde tutulmaktadır.
9-12 Byte: m_PrevPage= 4913 (Hexadecimal=31 13 00 00) 4913 sayısının hexadecimal karşılığı 00 00 13 31 ‘dir. m_PrevPage ifadesi ilgili Page’den önceki PageID bilgisinin FileID kısmından sonrasını verir. Bu değer ilgili Page değerinden 1 eksik olmak zorunda değildir. O page üzerindeki Key değerine göre bir önceki verilerin bulunduğu page bilgisidir.
13-14. Byte: m_prevPage=1 (Hexadecimal 01 00) Hexadecimal ifadeyi 00 01 olarak okumamız gerekir. Bu bilgi bize bir önceki Page’in FileID’sini vermektedir.
15-16. Byte: pminlen=41 (Hexadecimal 29 00) 41 sayısının hexadecimal karşılığı 00 29’dur. Pminlen bize sabit uzunlukta olan kolonların toplam byte değerini verir.
17-20. Byte: m_nextPage =1249 (Hexadecimal e1 04 00 00) 1249 sayısının hexadecimal karşılığı 00 00 04 e1’dir. m_nextPage bilgisi bir sonraki Page’in ID’sini verir. Bu bilgide FileID bulunmamaktadır.
21-22. Byte: m_nextPage=1 (Hexadecimal 01 00) Bir sonraki Page’in FileID’si bulunmaktadır.
23-24. Byte: slotcnt= 5 (Hexadecimal 0500) İlgili Page’deki toplam kayıt sayısını verir.
25-28. Byte: m_objID=240 (Hexadecimal f0 00 00 00) 240 sayısının hexadecimal karşılığı 00 00 00 f0’dır. m_objID, Allocation Unit ID’ye göre olan Object ID değeridir. OBJECT_ID fonksiyonu ile gelen Metadata ObjectID ise lookup tablolarda tutulmaktadır.
29-30. Byte: m_freeCnt= 1252 (Hexadecimal e4 04) 1252 sayısının hexadecimal karşılığı 04 e4’tür. m_freeCnt, Page içindeki boş alanın byte değeridir.
31-32. Byte: m_freeData = 6930 (Hexadecimal 12 1b) 6930 sayısının hexadecimal karşılığı 1b 12’dir. m_freeData, ilk byte değerinden içi dolu olan son byte değerine kadar olan değeri verir.
33-36. Byte: m_pageID =1248 (Hexadecimal e0 04 00 00) 1248 sayısının hexadecimal karşılığı 00 00 04 e0’dır. İlgili Page’in ID değerini FileID olmadan verir.
37-38. Byte: m_pageID =1 (Hexadecimal 0100) İlgili Page’in FileID değerini verir.
39-40. Byte: m_reservedCnt=0 (Hexadecimal 00 00) Page üzerinde Active Transaction tarafından ayrılmış olan byte değerini verir.
41-44. Byte: m_lsn= 42 (Hexadecimal=2a 00 00 00) 42 sayısının Hexadecimal karşılığı 00 00 00 2a’dır. İlgili Page üzerinde yapılan son değişikliğe ait lsn bilgisinin ilk kısmını tutar.
44-48. Byte: m_lsn= 6456 (Hexadecimal=38 19 00 00) 6456 saysının Hexadecimal karşılığı 00 00 19 38’dir. İlgili Page üzerinde yapılan son değişikliğe ait lsn bilgisinin ikinci kısmını tutar.
49-52. Byte: m_lsn= 54 (Hexadecimal= 36 00 00 00) 54 sayısının Hexadecimal karşılığı 00 00 00 36’dır. İlgili Page üzerinde yapılan son değişikliğe ait lsn bilgisinin üçüncü kısmını tutar.
53-56. Byte: m_xdesID= 1545 (09 06 00 00) m_xdesID bilgisi, m_reservedCnt alanında son değişikliği yapan Internal ID değerini verir. m_xdesID’nin ikinci kısmı bu alandadır.
57-58. Byte: m_xdesID= 0 (00 00) m_xdesID’nin ilk kısmı bu alandadır.
59-60. Byte: m_ghostRecCnt= 0 (00 00) Ghost kayıt sayısını verir.
61-64. Byte: m_tornBits= 1868363382 (76 f6 5c 6f) 1868363382 sayısının Hexadecimal karşılığı 6f 5c f6 76’dır. m_tornBits, Veritabanı seçeneğine göre ya TornBit değerini ya da Checksum değerini verir.
Kalan 32 Byte’lık kısımda ise 0 değeri bulunmaktadır.